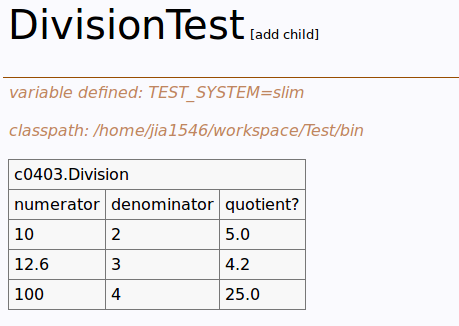
script table 主要用于检测软件的行为是否正确,比如模拟用户登录过程,堆栈操作过程等等。
script table 的格式是:
第一行关键字Script + 测试类的名字 表明这是一个script table
以后的每一行都对应类中的一个行为,并且可以加上关键字check, ensure, reject, show, start 等等来检测行为是否正确执行。这些关键字的含义见:http://fitnesse.org/FitNesse.UserGuide.SliM.ScriptTable 这里主要用到check, check关键字位于第一列,后面是带有返回值的函数,最后是期望输出的值。如果两者相等则此列标识为绿色,否则为红色。
这次的作业是检测 Java 1.7中双端队列(Double Ended Queue)中栈的实现是否正确,所谓双端队列就是可以从队列两端进行元素的插入和删除,如果从一端插入,从另一端删除,则是队列,从同一端删除则是栈。用script table 来检测栈的四种行为:instantiate, push(e), pop(), peek(),同时检查栈是否是LIFO的
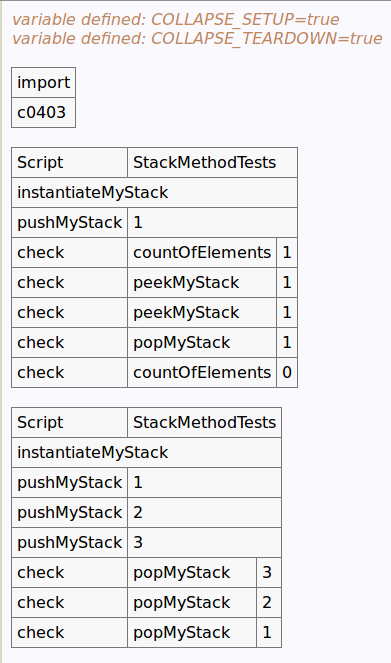
用于生成script table的代码为:
!define TEST_SYSTEM {slim}
!path /home/jia1546/workspace/Test/bin
!define COLLAPSE_SETUP {true}
!define COLLAPSE_TEARDOWN {true}
|import|
|c0403 |
!|Script |StackMethodTests |
|instantiateMyStack |
|pushMyStack|1 |
|check |countOfElements|1|
|check |peekMyStack |1|
|check |peekMyStack |1|
|check |popMyStack |1|
|check |countOfElements|0|
!|Script |StackMethodTests|
|instantiateMyStack |
|pushMyStack|1 |
|pushMyStack|2 |
|pushMyStack|3 |
|check |popMyStack |3 |
|check |popMyStack |2 |
|check |popMyStack |1 |
生成的script table为:
对应测试类的代码为:
package c0403;
import java.util.ArrayDeque;
import java.util.Deque;
import java.math.*;
public class StackMethodTests {
private int num;
private Deque<Integer> theStack;
final int SCALE = 1000; //define the range of the random integer
final int TIMES = 100; //define the times used in Different-But-Equivalent technique
public void instantiateMyStack(){
//theStack = StaticStack.myStack;
theStack = new ArrayDeque<Integer>();
}
public void pushMyStack(int num){
theStack.addFirst(num);
}
public int popMyStack(){
return theStack.removeFirst();
}
public int peekMyStack(){
return theStack.peekFirst();
}
public int countOfElements(){
return theStack.size();
}
/*
* push 100 elements and then pop those 100 elements
*/
public void pushThenPop(){
for(int i=0; i<TIMES; i++){
int n = (int)(Math.random() * SCALE);
this.pushMyStack(n);
}
for(int i=0; i<TIMES; i++){
this.popMyStack();
}
}
/*
* push and pop a random element 100 times
*/
public void pushAndPop(){
for(int i=0; i<TIMES; i++){
int n = (int)(Math.random() * SCALE);
this.pushMyStack(n);
this.popMyStack();
}
}
}
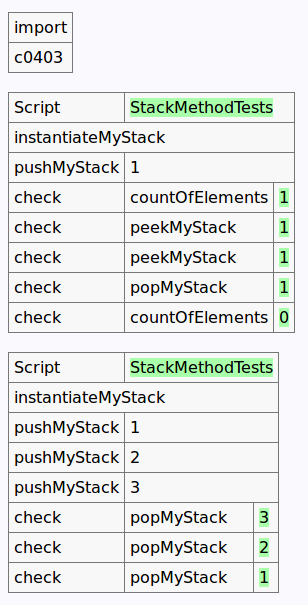
测试结果为:
PS: 最近的deadline太多了,接下来是有关performance test的测试工具JMemter的话题。
 = \frac{1-d}{n}+d \sum_{p_{j}\in M(p_{i})} \frac{PR(p_{j})}{L(p_{j})}$") ,其中
,其中$") 是顶点
是顶点 的PageRank值,
的PageRank值,$") 是顶点
是顶点 的出度。
的出度。 = \frac{1-d}{n}+d \sum_{p_{j}\in M(p_{i})} \frac{weight(p_{j}) \times PR(p_{j})}{degree(p_{j})}$") 其中
其中$") 是边
是边$") 的权重,
的权重,$") 是顶点
是顶点